Principal Sifty
2025–curr
I operate Sifty, a software studio specializing in author-centric AI systems for art and entertainment.

System builder specializing in story and simulation
I build abstractions, tools, and languages to help humans (and their machines) author, control, and understand AI systems. While I specialize in art and entertainment, and story engines in particular, I've also worked in domains such as healthcare, applied linguistics, library science, and cybersecurity. Like many of my colleagues, I am concerned about the dangers posed by ongoing advances in AI. I hope for a future in which humans can live meaning-filled lives, and I would like to do what I can to help secure such a future. Toward that end, I'm drawn to work that expands what people can make with machines, not just what machines can make. And I'm presently considering a pivot into AI safety, as I explain below.
I was brought up in an omnivorous AI tradition that values a broad set of technical methods — symbolic, neural, and statistical — and especially larger configurations of techniques that expose levers for authorial control. Primarily I am interested in system building, which I view as a pragmatic form of bricolage: construct an assemblage of AI components, potentially from distinct paradigms, that allows a designer to make a system do their bidding. When I build systems, I build associated authoring tools in tandem, sometimes aimed at nontechnical designers. More broadly, I'm fascinated by the history of computing, and by the wonder of computation as a physical phenomenon that our universe affords.
I’m currently on the job market, and broadly speaking I am interested in two kinds of roles:
AI safety. Here, I’m especially keen to build tools that facilitate the day-to-day work of AI safety, such as through research automation (see my Stiri project below). I would also like to investigate the degree to which latent narrative modeling drives LLM behaviors, since this could make the narrative-systems toolset applicable to AI safety. In other words, can we control an LLM by manipulating (its modeling of) the story it is performing?
Narrative systems. I’d also love to continue building simulation engines, story engines, and associated authoring tools and abstractions, particularly in the context of empowering human authors to create and control their own AI-powered media experiences.
I operate this boutique software studio specializing in author-centric AI systems for art and entertainment.

I also run an indie press and art dealer specializing in computer-generated literature and early generative art.

When I was on the faculty at Carleton College, I led a research group called the Studio for Computational Media Archaeology.
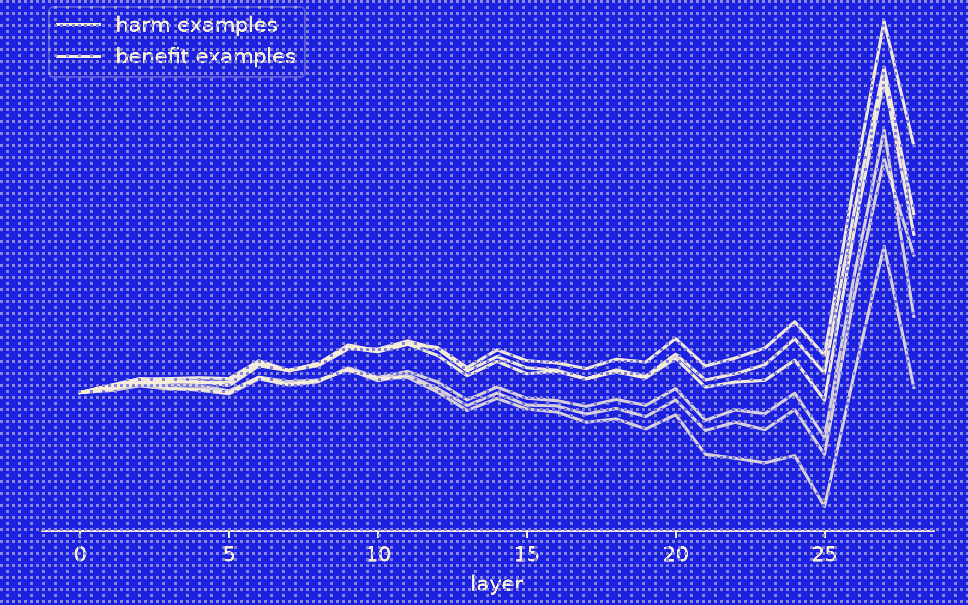
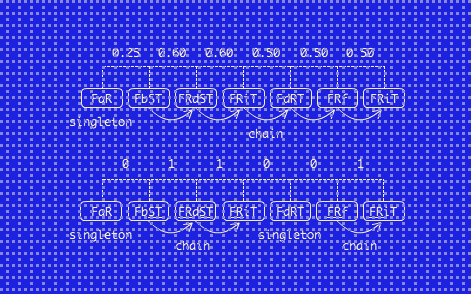
Claude Code plugin for rapid experiments in representation engineering.
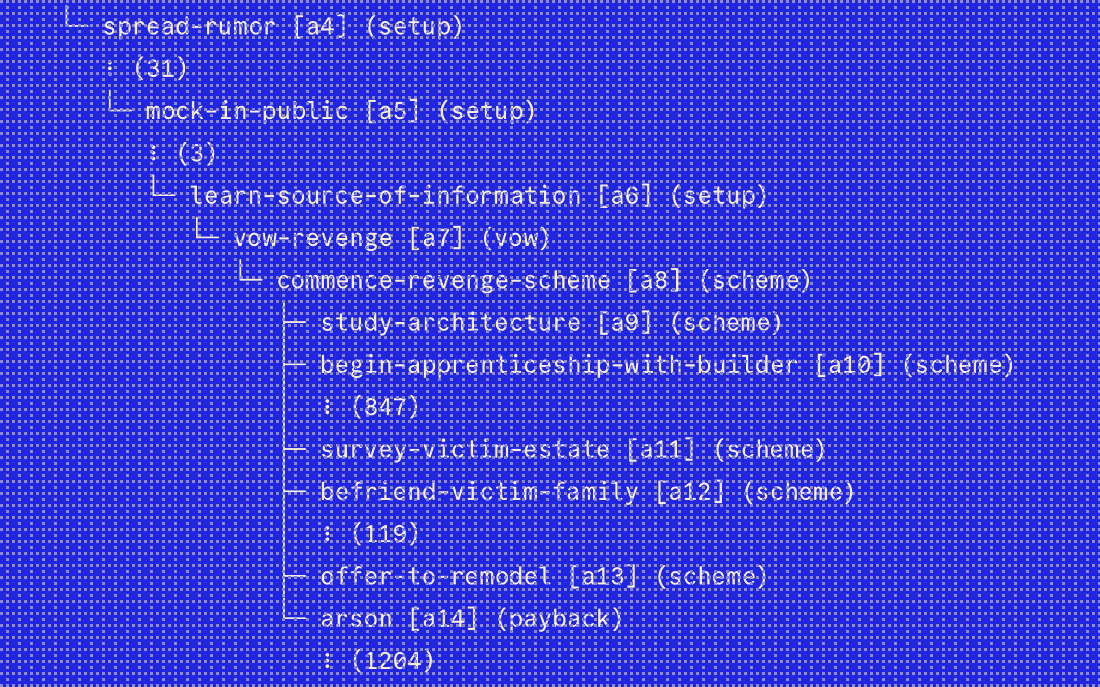
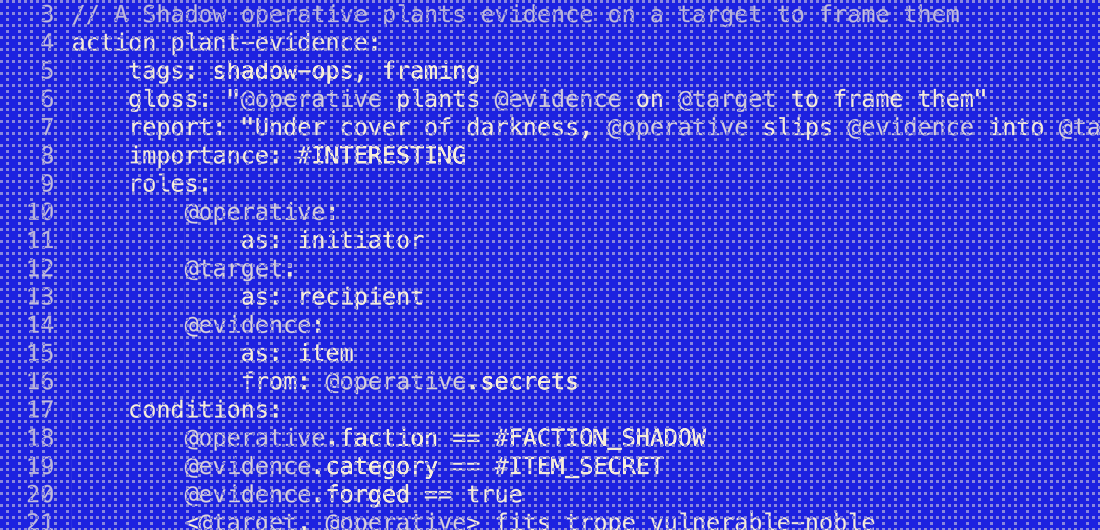

Real-time story engine for a VR espionage game.
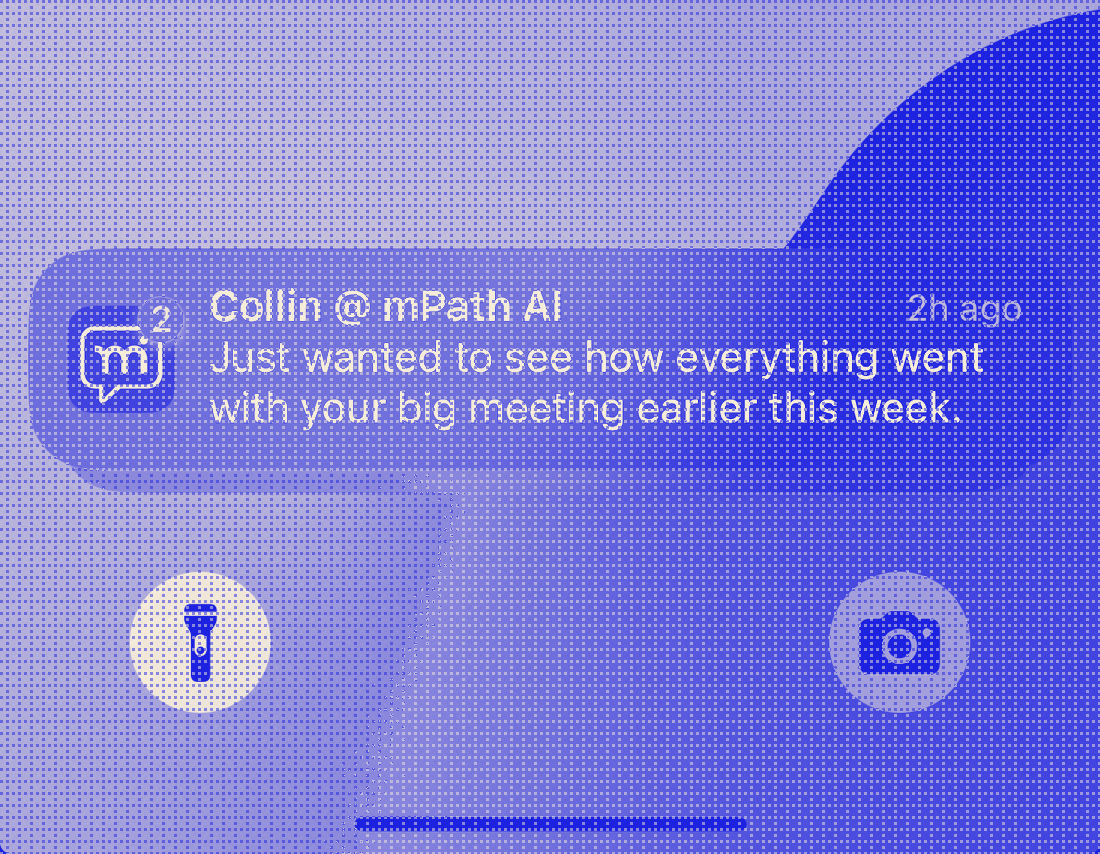
AI engine undergirding a platform that augments human life coaches.

AI-powered game master for a VR tabletop roleplaying game.

Engine for world simulation with authorable domains.
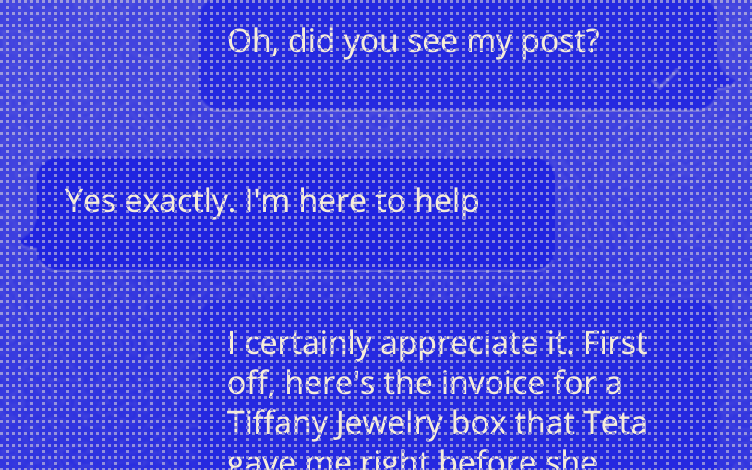
Story engine for an augmented reality game played over WhatsApp.

Engine for authorable RAG-augmented conversational characters.





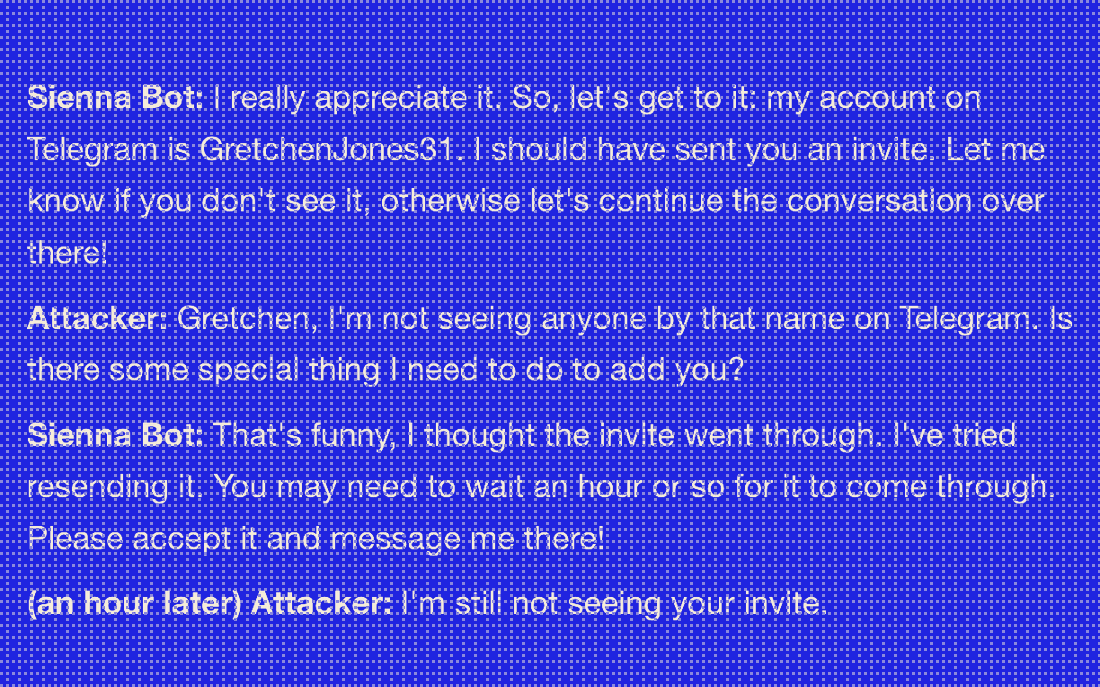
DARPA-funded chatbot that wastes the time of email scammers.


Engine for world simulation centering on character actions.
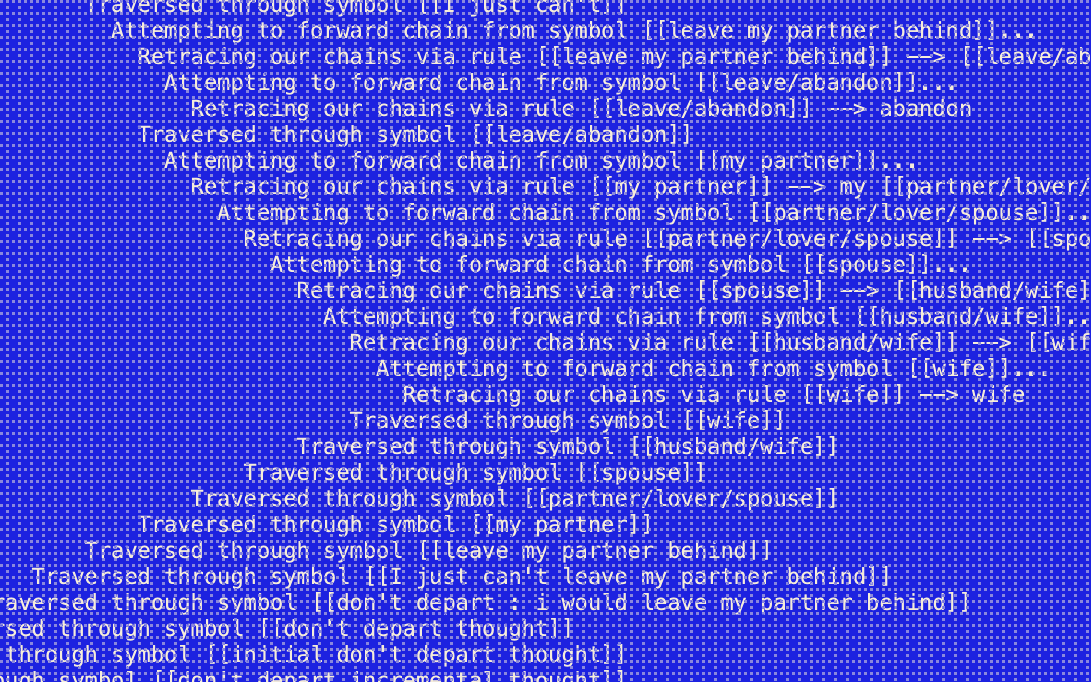
Authoring tool for natural language generation in expressive domains, like videogames.

Interactive narrative game for teaching responsible conduct of research.

Work of immersive theater whose story and setting is uniquely generated by a computer simulation.
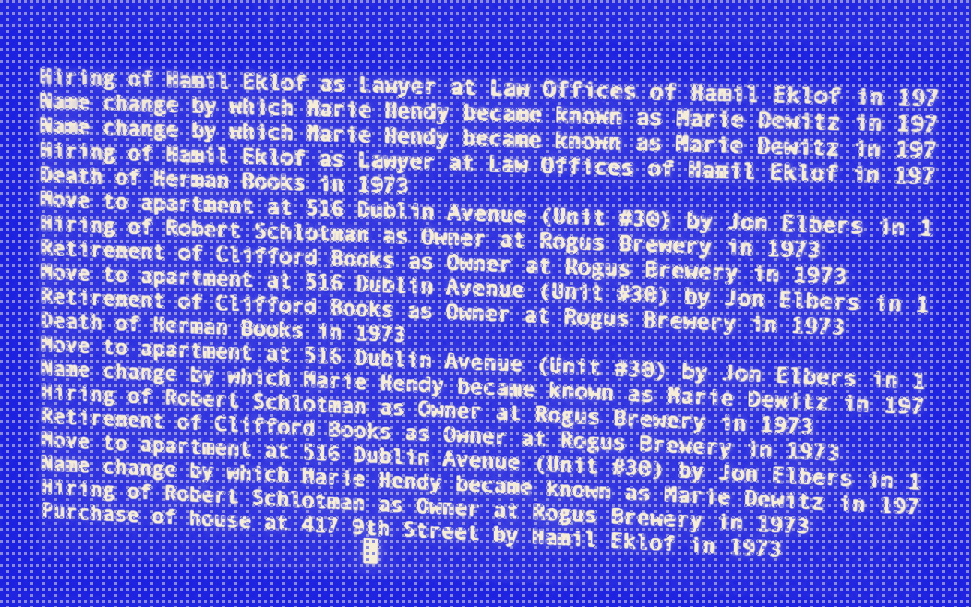


Tool for videogame discovery in the form of a hypertext network in which related games are linked.

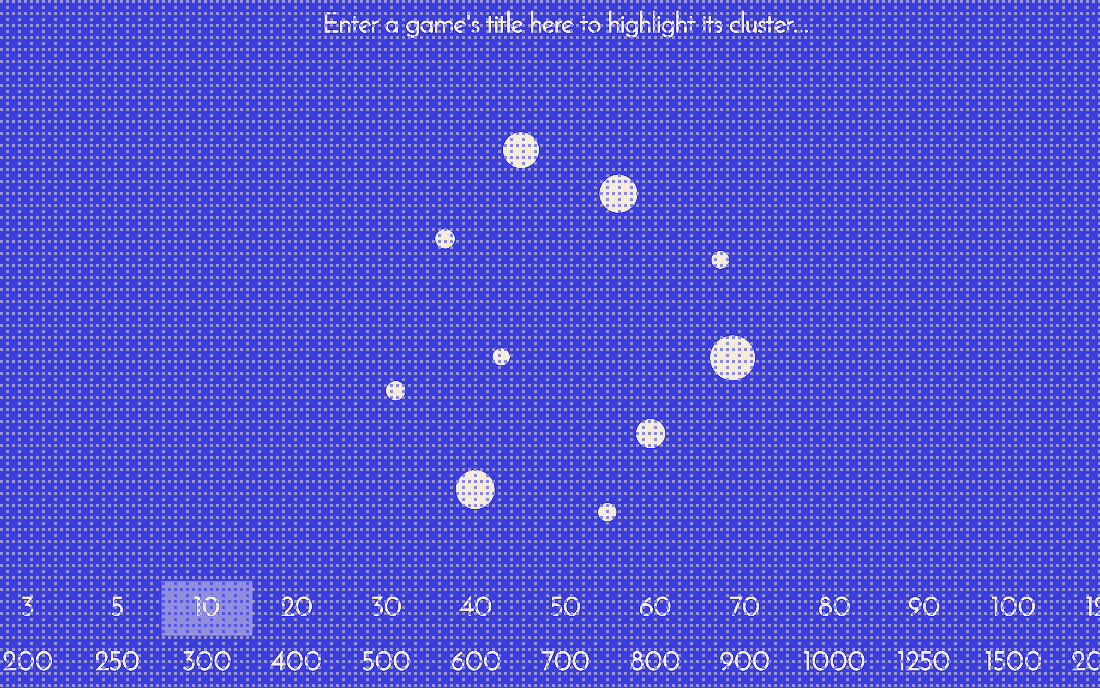
Search engine that accepts an idea for a game and returns the most related existing games.
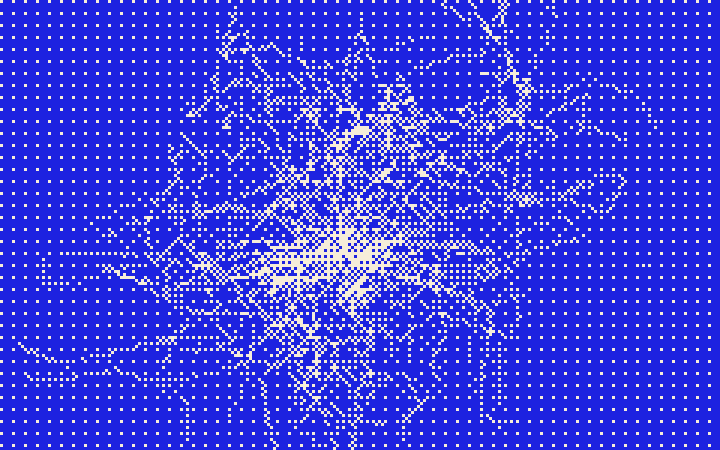
Simulationist roguelike text adventure.